Lecture 02: Probability and Random Variables
Joseph Rudoler
2026-01-06
\[ \renewcommand{\P}{\mathbb{P}} \newcommand{\E}{\mathbb{E}} \newcommand{\Var}{\mathbb{V}\text{ar}} \newcommand{\Cov}{\mathbb{C}\text{ov}} \]
Probability
Most of you are probably familiar with the basic intuition of probability: essentially it measures how likely an event is to occur.
In mathematical terms, the probability \(\P\) of an event \(A\) is defined as:
\[ \P(A) = \frac{\text{ \# of outcomes where } A \text{ occurs}}{\text{ total \# of outcomes}} \]
By definition this quantity:
- cannot be negative (\(\P(A) = 0\) means \(A\) never occurs), and
- it must be less than or equal to 1 (\(\P(A) = 1\) means \(A\) always occurs).
Example: Coin Flip
The classical example of probability is flipping a coin. When you flip a fair coin, there are two possible outcomes: heads (\(H\)) and tails (\(T\)).
If we let \(A\) be the event that the coin lands on heads, then we can compute the probability of \(A\) as follows:
\[ \P(\text{H}) = \frac{\text{ \# of heads}}{\text{ total \# of outcomes}} = \frac{1}{2} \]
This matches our intuition that a fair coin has a 50% chance of landing on heads.
Properties of Probability: Sum to 1
An important property of probabilities is that the sum of the probabilities of all possible outcomes must equal 1. This is like say “there’s a 100% chance that something will happen”.
In our coin flip example, we have two possible outcomes: heads and tails. If the coin flip is not heads, it must be tails. In other words, the events \(H\) and \(T\) cover 100% of the possible outcomes. So we can write: \[ \P(H) + \P(T) = 1 \quad \Rightarrow \quad \frac{1}{2} + \frac{1}{2} = 1 \]
When we know the events we are interested in make up all of the possible outcomes, we can use this property to compute probabilities.
For example, for any event \(A\), the event either happens or it doesn’t. So we can compute the probability of the event not occurring as: \[ \P(\text{not}~ A) = 1 - \P(A) \]
Probability of multiple events
But what if we flip the coin twice?
Now there are four possible outcomes:
- \(HH\)
- \(HT\)
- \(TH\)
- \(TT\)
If we let \(B\) be the event that at least one coin lands on heads, we can compute the probability of \(B\) as follows:
\[ \P(B) = \frac{\text{ \# of outcomes with at least one head}}{\text{ total \# of outcomes}} = \frac{|\{HH, HT, TH\}|}{|\{HH, HT, TH, TT\}|} = \frac{3}{4} \]
Probability of multiple events: AND vs OR
What is the probability of getting heads on the first flip AND the second flip (i.e., the event \(C = \{HH\}\))?
- There is only one outcome where both flips are heads
- Still four total outcomes
- \(\P(C) = \P (H_1 ~\text{and}~ H_2) = \frac{1}{4}\).
What about the probability of getting heads on the first flip OR the second flip?
This is actually the same event as \(B\) before (at least 1 heads), so we can use the same calculation:
\(\P(B) = \P(H_1 ~\text{or}~ H_2) = \frac{3}{4}\).
Set notation (AND / OR)
In the above, we used \(H_1\) and \(H_2\) to denote heads on the first and second flips, respectively.
The notation \(H_1 ~\text{and}~ H_2\) means both flips are heads, while \(H_1 ~\text{or}~ H_2\) means at least one flip is heads.
In probability theory, we often use the symbols \(\cap\) and \(\cup\) to denote “and” and “or” respectively.
So we could also write \(\P(H_1 \cap H_2)\) for the probability of both flips being heads, and \(\P(H_1 \cup H_2)\) for the probability of at least one flip being heads.
Technically, this is set notation where \(\cap\) means intersection (the event where both \(H_1\) and \(H_2\) occur), while \(\cup\) means union (the event where either \(H_1\) or \(H_2\) occurs).
Addition rule
For any two events \(A\) and \(B\), the probability of either \(A\) or \(B\) occurring is given by: \[ \P(A \cup B) = \P(A) + \P(B) - \P(A \cap B) \] This last term, \(\P(A \cap B)\), is necessary to avoid double counting the outcomes where both \(A\) and \(B\) occur.
Note that if \(A\) and \(B\) are mutually exclusive (i.e., they cannot both occur at the same time), then \(\P(A \cap B) = 0\), and the formula simplifies to: \[ \P(A \cup B) = \P(A) + \P(B)\]
Visualizing sets of events
Visualizing sets of events
The following image illustrates the addition rule for two events \(A\) and \(B\) using a Venn diagram. 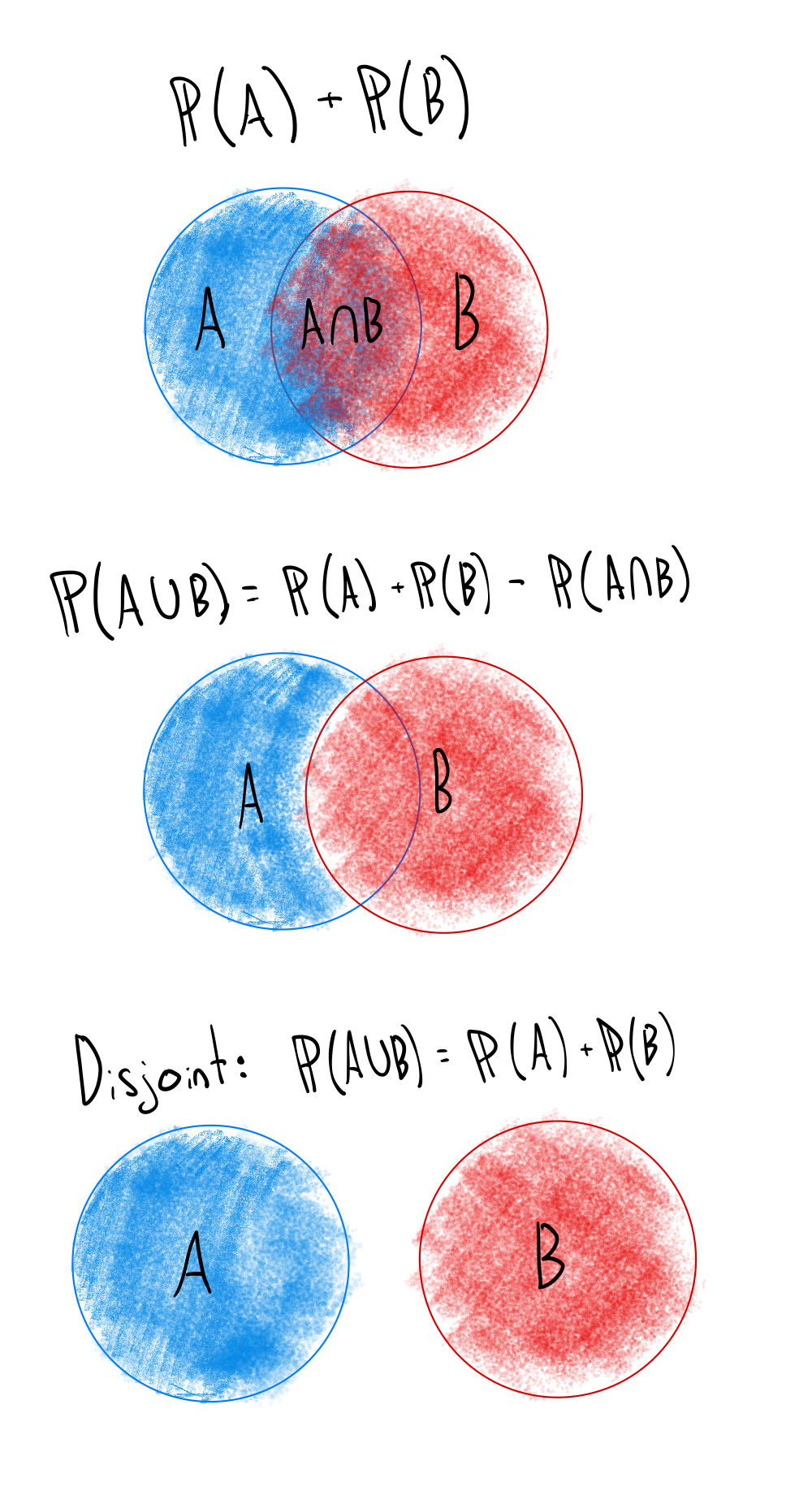
Multiplication rule
For any two events \(A\) and \(B\), the probability of both \(A\) and \(B\) occurring is given by: \[\P(A \cap B) = \P(A) \cdot \P(B | A)\] where \(\P(B | A)\) is the conditional probability of \(B\) given that \(A\) has occurred. This means you first consider the outcomes where \(A\) occurs, and then look at the probability of \(B\) within that subset.
Conditional probability
Conditional probability
The notation \(\P(B | A)\) is read as “the probability of \(B\) given \(A\)”. It represents the probability of event \(B\) occurring under the condition that event \(A\) has already occurred.
We make these adjustments in our heads all of the time.
- For example, you might expect that it is more likely I will buy ice cream if it is hot outside. In this case, the event \(A\) is “it is hot outside”, and the event \(B\) is “I buy ice cream”.
- The conditional probability \(\P(B | A)\) would be higher than \(\P(B)\) on a typical day.
Conditional probability example
Let’s think about this in the context of our coin flips. If we know that the first flip is heads (\(H_1\)), then only two outcomes are possible (\(HH\) and \(HT\)) instead of four (\(HH\), \(HT\), \(TH\), \(TT\)).
- The conditional probability \(\P(H_2 | H_1)\), which is the probability of the second flip being heads given that the first flip was heads, is: \[ \P(H_2 | H_1) = \frac{\text{ \# of outcomes where } H_2 \text{ occurs and } H_1 \text{ has occurred}}{\text{ total \# of outcomes where } H_1 \text{ has occurred}} = \frac{|\{HH\}|}{|\{HH, HT\}|} = \frac{1}{2} \]
The multiplication rule helps us calculate the probability of multiple events happening, as long as we know how one event affects the other (i.e., the conditional probability).
Problem: Drawing Cards
Consider a deck of cards (52 cards total, 13 of each suit). I might ask you, “What is the probability of drawing a club on the first draw and a club on the second draw? (Assuming you do not replace the first card.)”
Independence
Two events \(A\) and \(B\) are said to be independent if the occurrence of one does not affect the probability of the other.
How does this relate to the multiplication rule?
- If \(A\) and \(B\) are independent, then the conditional probability \(\P(B | A)\) is simply \(\P(B)\).
- Knowing that \(A\) has occurred does not change the probability of \(B\) occurring.
This means that for independent events, the multiplication rule simplifies to:
\[\P(A \cap B) = \P(A) \cdot \P(B)\]
Independence example
Our coin flip example illustrates this nicely.
- If we flip a fair coin twice, the outcome of the first flip does not affect the outcome of the second flip.
- Therefore, the two events (the first flip being heads and the second flip being heads) are independent.
So the probability of both flips being heads is simply
\[\P(H_1 \cap H_2) = \P(H_1) \cdot \P(H_2) = \frac{1}{2} \cdot \frac{1}{2} = \frac{1}{4}\]
Complicated counting
Counting gets confusing and cumbersome quickly, especially when we have many events or outcomes.
Say that I want to know the probability of getting exactly one head when flipping a coin 5 times.
Let’s think about the case where the first flip is heads.
- The probability of getting a head on the first flip is \(\frac{1}{2}\), and the probability of getting tails on the 4 other flips is also \(\frac{1}{2}\) each.
- Because the flips are independent, we can multiply these probabilities together to get the probability of this specific sequence of flips: \[\P(H_1 \cap T_2 \cap T_3 \ldots \cap T_{5}) = \frac{1}{2} \cdot \left(\frac{1}{2}\right)^4 = \frac{1}{2^{5}}\]
Complicated counting (cont.)
Are we done? As it stands, this is the probability of getting heads on the first flip and tails on all other flips.
- But there are many other sequences that would also meet the conditions of getting “exactly one head”
- For example, we could have heads on the second flip and tails on all other flips, or heads on the third flip and tails on all other flips, and so on.
- In fact, there are exactly 5 different sequences that would meet the conditions of getting exactly one head in 5 flips. So we need to multiply our previous result by the number of sequences that meet the conditions: \[\P(\text{exactly one head in 5 flips}) = 5 \cdot \frac{1}{2^{5}} = \frac{5}{32} \approx .16\]
Counting Outcomes
There are two common types of outcomes we want to count: permutations and combinations.
A combination is a selection of items or events without regard to the order in which they occur. For example, the number of ways 1 out of 5 flips could be heads.
An important and intuitive way to think about combinations is that we are choosing an item from a set. In our example, we are choosing 1 flip to be heads out of 5 flips.
\[ \begin{align*} \text{Flip 1 is heads} &= \{1, 0, 0, 0, 0\} \\ \text{Flip 2 is heads} &= \{0, 1, 0, 0, 0\} \\ \text{Flip 3 is heads} &= \{0, 0, 1, 0, 0\} \\ \vdots \\ \text{Flip 5 is heads} &= \{0, 0, 0, 0, 1\} \end{align*} \]
It is clear here that there are 5 possible “slots” where we can place a head.
Choosing 2 heads from 5 flips
What if we want to know the number of ways to choose 2 flips to be heads out of 5 flips? Naturally the logic above still applies, and the 5 flips we counted above are still all valid placements for one of the two heads. Now we just need to consider the second head.
Let’s take the first row from above, where the first flip is heads. Given that the first flip is heads, how many ways can we choose a second flip to also be heads? The second flip can be any of the remaining 4 flips, so there are 4 possible choices. \[ \begin{align*} \text{Flip 1 and 2 are heads} &= \{1, 1, 0, 0, 0\} \\ \text{Flip 1 and 3 are heads} &= \{1, 0, 1, 0, 0\} \\ \text{Flip 1 and 4 are heads} &= \{1, 0, 0, 1, 0\} \\ \text{Flip 1 and 5 are heads} &= \{1, 0, 0, 0, 1\} \end{align*} \]
Counting continued
Now let’s consider the second row, where the second flip is heads. Given that the second flip is heads, how many ways can we choose a first flip to also be heads? The first flip can be any of the remaining 4 flips, so there are again 4 possible choices.
\[ \begin{align*} \text{Flip 2 and 1 are heads} &= \{1, 1, 0, 0, 0\} \\ \text{Flip 2 and 3 are heads} &= \{0, 1, 1, 0, 0\} \\ \text{Flip 2 and 4 are heads} &= \{0, 1, 0, 1, 0\} \\ \text{Flip 2 and 5 are heads} &= \{0, 1, 0, 0, 1\} \end{align*} \]
You would continue this process for the third, fourth, and fifth flips. So for each of the 5 flips, you can choose any of the remaining 4 flips to be heads.
This gives us a total of \(5 \cdot 4 = 20\) ways to choose 2 flips to be heads out of 5 flips.
But wait! We already counted the combination of flips 2 and 1 earlier (just in a different order – where flip 1 was heads first).
Permutations vs Combinations
This illustrates the key distinction between combinations and permutations. A permutation is an arrangement of items or events in a specific order.
- Every possible combination of heads can be arranged in different ways, leading to different sequences of flips.
- If you are only interested in counting combinations, listing out all of the possible arrangements like we did above leads to double counting.
Counting all of the possible permutations of a sequence is straightforward. Using the logic above, you just assign “slots” in a sequence to each of the items you are arranging.
Each time you allocate a slot, you have one fewer item to place in the remaining slots. So for a sequence of length \(n\), the number of permutations is: \[ n! = n \cdot (n-1) \cdot (n-2) \cdots 2 \cdot 1 \]
Combination formula
Now, if we want to count combinations instead of permutations, we start with the number of permutations and then discount to account for the fact that the order does not matter.
Namely, the number of combinations of \(k\) items from a set of \(n\) items is given by the formula: \[ \binom{n}{k} = \frac{n!}{k! \cdot (n-k)!} \]
This formula:
- counts all of the possible permutations of the sequence (\(n!\))
- divides by the number of ways to arrange the \(k\) items that are selected (which is \(k!\))
- divides by the number of ways to arrange the remaining \(n-k\) items (which is \((n-k)!\)).
Combination example
In our example, we have \(n = 5\) (the number of flips) and \(k = 2\) (the number of heads). So the number of combinations of 2 heads from 5 flips is: \[ \binom{5}{2} = \frac{5!}{2! \cdot (5-2)!} = \frac{5!}{2! \cdot 3!} = \frac{5 \cdot 4 \cdot 3!}{2 \cdot 1 \cdot 3!} = \frac{5 \cdot 4}{2 \cdot 1} = 10 \]
End of Part 1
This concludes the first part of our lecture on probability. We have covered the basic concepts of probability, how to compute probabilities for single and multiple events, and the distinction between combinations and permutations. Next we will talk about probability functions, which allow us to concisely describe the probability of outcomes that have many possible values.
Probability functions
Thinking about probability in terms of counting outcomes is useful, and it is always a good idea to keep that intuition in mind if you ever get stuck.
However, it is often more convenient to work with probability functions.
- assigns a probability to each possible outcome. For example, if we have a fair coin, we can define a probability function \(f\) as follows: \[ f(x) = \begin{cases} \frac{1}{2} & \text{if } x = 0 \text{ (heads)} \\ \frac{1}{2} & \text{if } x = 1 \text{ (tails)} \\ 0 & \text{otherwise} \end{cases} \] where \(x\) is the outcome of the coin flip (0 for heads, 1 for tails).
Probability functions are concise
Functions map inputs to outputs
Functions are just a “map” that tells you what output to expect for each input. A probability function is a special type of function that maps inputs to probabilities in the range \([0, 1]\).
This might seem a bit redundant because we’re just presenting the same information in a new format.
But probability functions are much more concise!
Die roll example
For example, if we have a die with six sides, we can define a probability function \(f\) as follows: \[ f(x) = \begin{cases} \frac{1}{6} & \text{if } x = 1, 2, 3, 4, 5, 6 \\ 0 & \text{otherwise} \end{cases} \]
But we can also use the same function to describe the probability of rolling a die with any number of sides. For example, if we have a die with \(k\) sides, we can define a probability function \(f\) as follows:
\[ f(x) = \begin{cases} \frac{1}{k} & \text{if } x = 1, 2, \ldots, k \\ 0 & \text{otherwise} \end{cases} \] This is much more concise than writing out the probability for each possible outcome, and it allows us to easily generalize to any number of sides.
Python implementation
Random Variables
A random variable is a quantity that
- can take on different values based on the outcome of a random event.
- it might be a discrete variable (like the outcome of a coin flip)
- it might be a continuous variable (like the height of a person).
- basically it is any quantity that has randomness associated with it.
We denote random variables with capital letters, like \(X\) or \(Y\). The specific values that a random variable can take on in a particular instance are usually denoted with lowercase letters, like \(x\) or \(y\).
Probability Functions for Random Variables
We use probability functions to describe the probabilities associated with random variables.
- Specifically, a probability function \(f\) for a random variable \(X\) gives the probability that \(X\) takes on a specific value \(x\).
For example, let \(X\) be a random variable that represents the outcome of flipping a fair coin. The probability function for \(X\) would be: \[ f(x) = \P (X = x) = \begin{cases} \frac{1}{2} & \text{if } x = 0 \text{ (heads)} \\ \frac{1}{2} & \text{if } x = 1 \text{ (tails)} \\ 0 & \text{otherwise} \end{cases} \]
Bernoulli random variable
Bernoulli random variable
The above is an example of a Bernoulli random variable, which takes on the value 1 with probability \(p\) and the value 0 with probability \(1 - p\). In our case, \(p = \frac{1}{2}\) for a fair coin.
Continuous random variables
As mentioned above, we can also think about random variables with continuous values. For example, let \(Y\) be a random variable that represents the height of a person in centimeters. Let’s assume that every person’s height is equally likely to be between 150 cm and 200 cm (this is not true of course). The probability function for \(Y\) would be: \[ f(y) = \P (Y = y) = \begin{cases} \frac{1}{50} & \text{if } 150 \leq y \leq 200 \\ 0 & \text{otherwise} \end{cases} \]
Uniform random variable
The above is an example of a uniform random variable, which takes on values in a continuous range with equal probability. In our case, the range is from 150 cm to 200 cm, and the probability density function is \(\frac{1}{50}\).
Random Variables for random processes
In statistics, we treat our data as a random variable (or a collection of random variables). What this means is that we assume that the data we observe is just one possible outcome of a random process.
This is a powerful assumption because it allows us to use probability theory to make inferences about the underlying process that generated the data. This is going to be a key idea in the next lecture and throughout the course.
Probability distributions
We call the probability function for a random variable a probability distribution
- describes how the probabilities are distributed across the possible values of the random variable.
Distributions can be discrete or continuous, depending on the type of random variable.
- for discrete random variables, the probability distribution is often represented as a probability mass function (PMF), which gives the probability of each possible value.
- for continuous random variables, the probability distribution is represented as a probability density function (PDF), which gives the density of probability at each point.
Visualizing Random Variables and Distributions
Let’s say we have a random variable \(X\), but we don’t know the exact probability function. Instead, we have a set of observed data points \(\{x_1, x_2, \ldots, x_n\}\) that we believe are individual realizations of \(X\). In other words, we have a sample of data that we think is representative of the underlying random variable.
How can we visualize this data to understand the distribution of \(X\)? The simplest solution is to just plot how many times each value occurs in the data. We can use a bar chart to visualize the counts of each value.
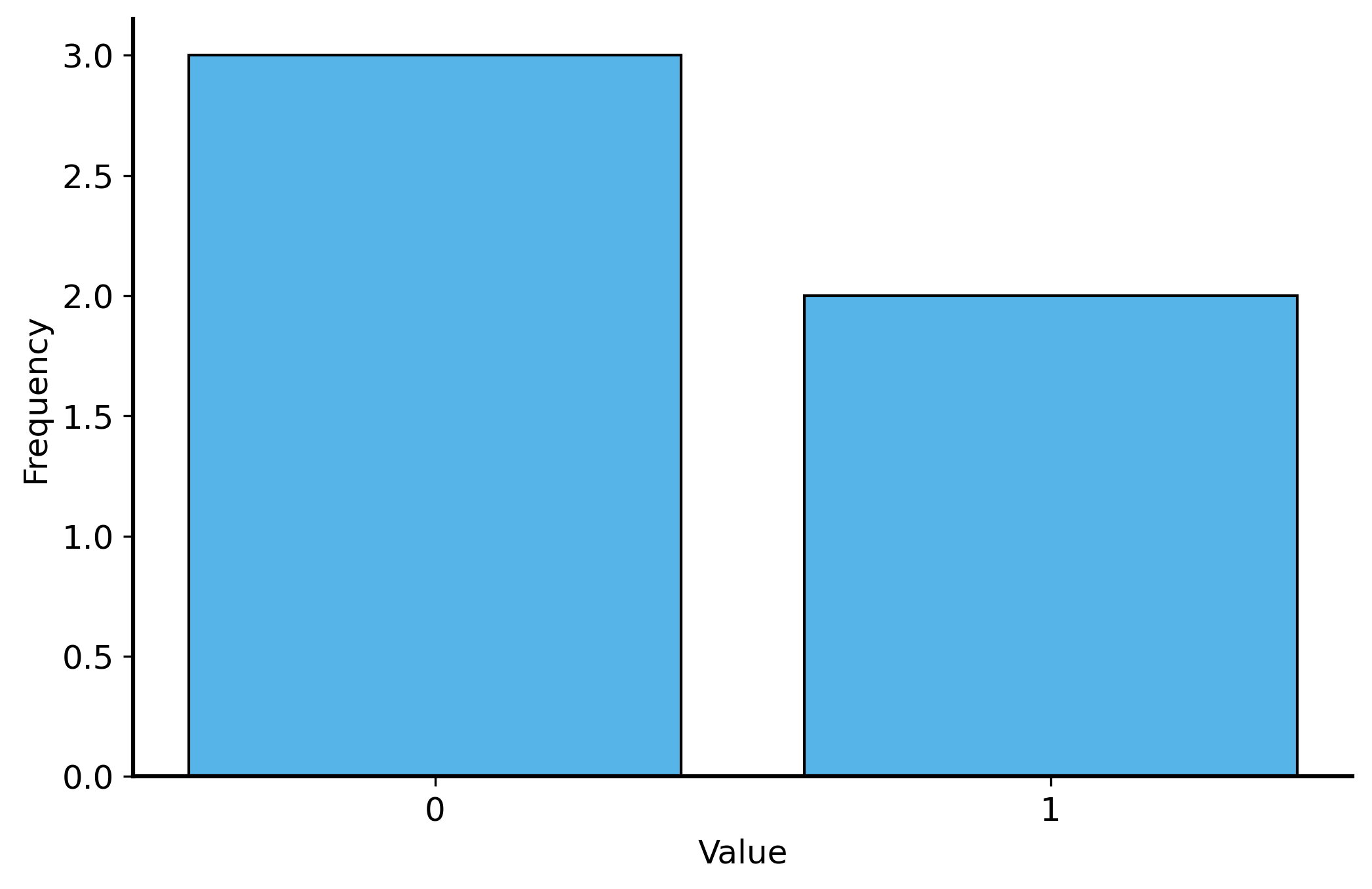
Example: Dice Rolls
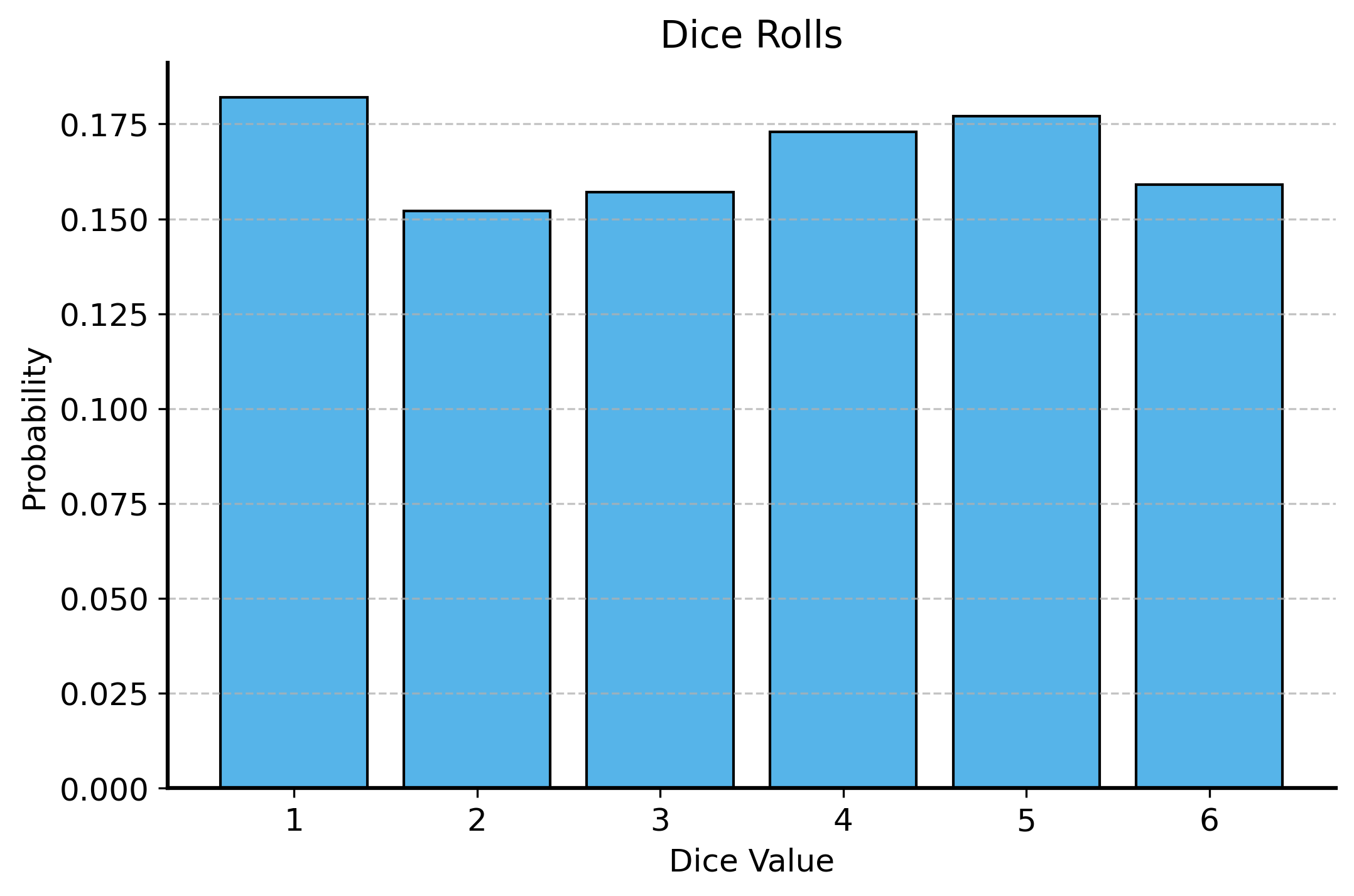
Consider a bunch of dice rolls. If we roll a die 100 times, we would expect to see each number appear roughly a similar number of times.
If we plot the frequencies of each roll, we should see a discrete uniform distribution, where each number from 1 to 6 has approximately the same height. Let’s check it out:
Total number of dice rolls: 1000| rolls | |
|---|---|
| 0 | 1 |
| 1 | 5 |
| 2 | 4 |
| 3 | 3 |
| 4 | 3 |
| 5 | 6 |
| 6 | 1 |
| 7 | 5 |
| 8 | 2 |
| 9 | 1 |
Dice Rolls Plot
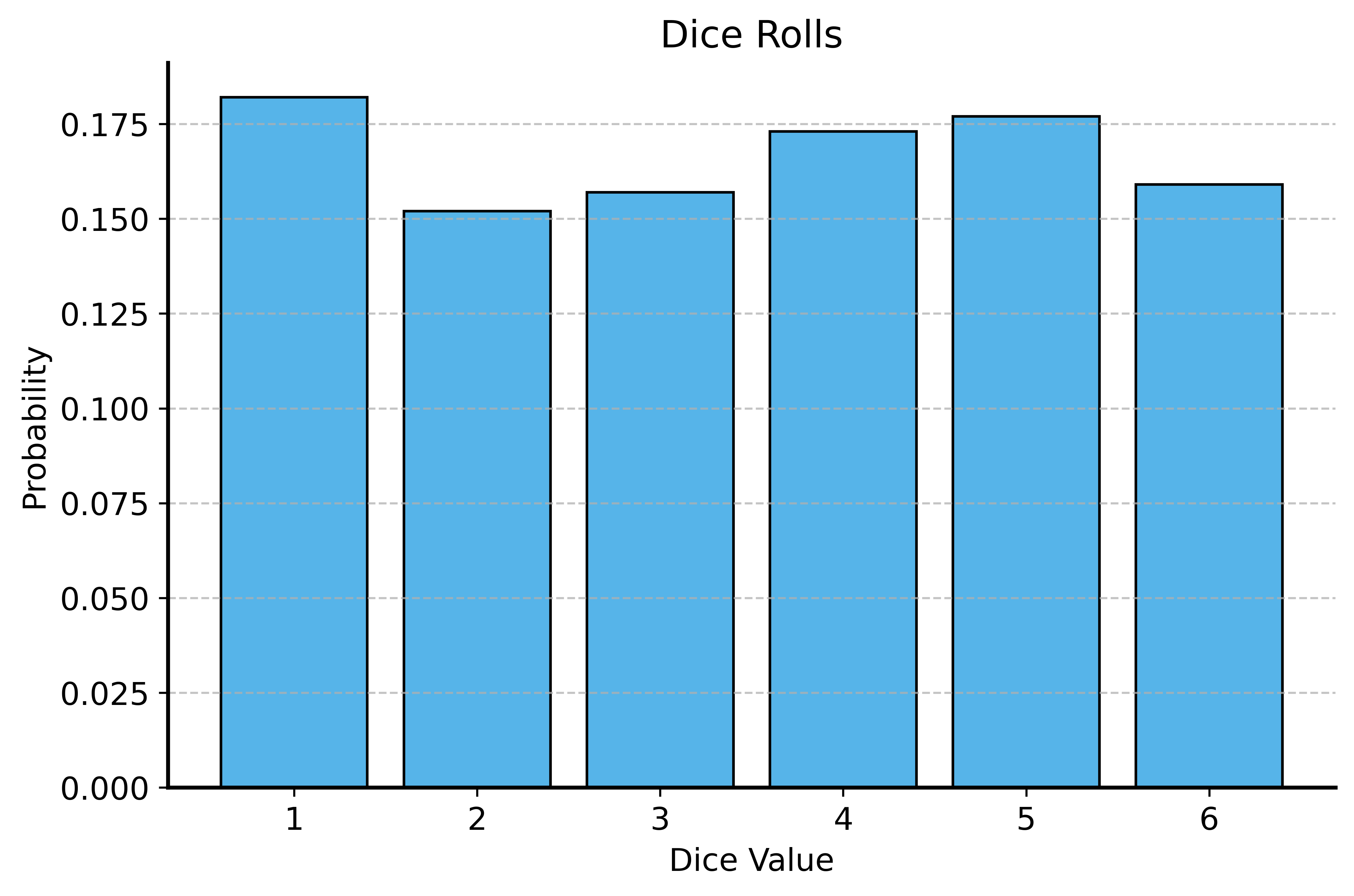
Notice that when the \(y\)-axis represents probabilities, the heights of the bars sum to 1. This is because the total probability of all possible outcomes must equal 1!
Histograms for Continuous Random Variables
What about continuous random variables? In this case, we cannot just count the number of occurrences of each value, because there are infinitely many possible values.
Instead, we can use a histogram to visualize the distribution of the data.
The histogram is a graphical representation that summarizes the distribution of a dataset.
- divides the data into discrete, equally-sized intervals (or “bins”) along the x-axis and counts how many data points fall into each bin.
- the height of each bar represents the either the total count of data points in that bin or the proportion of data points in that bin.
- if the height of the bar is the proportion, then the area of the bar represents the probability of the random variable falling within that bin.
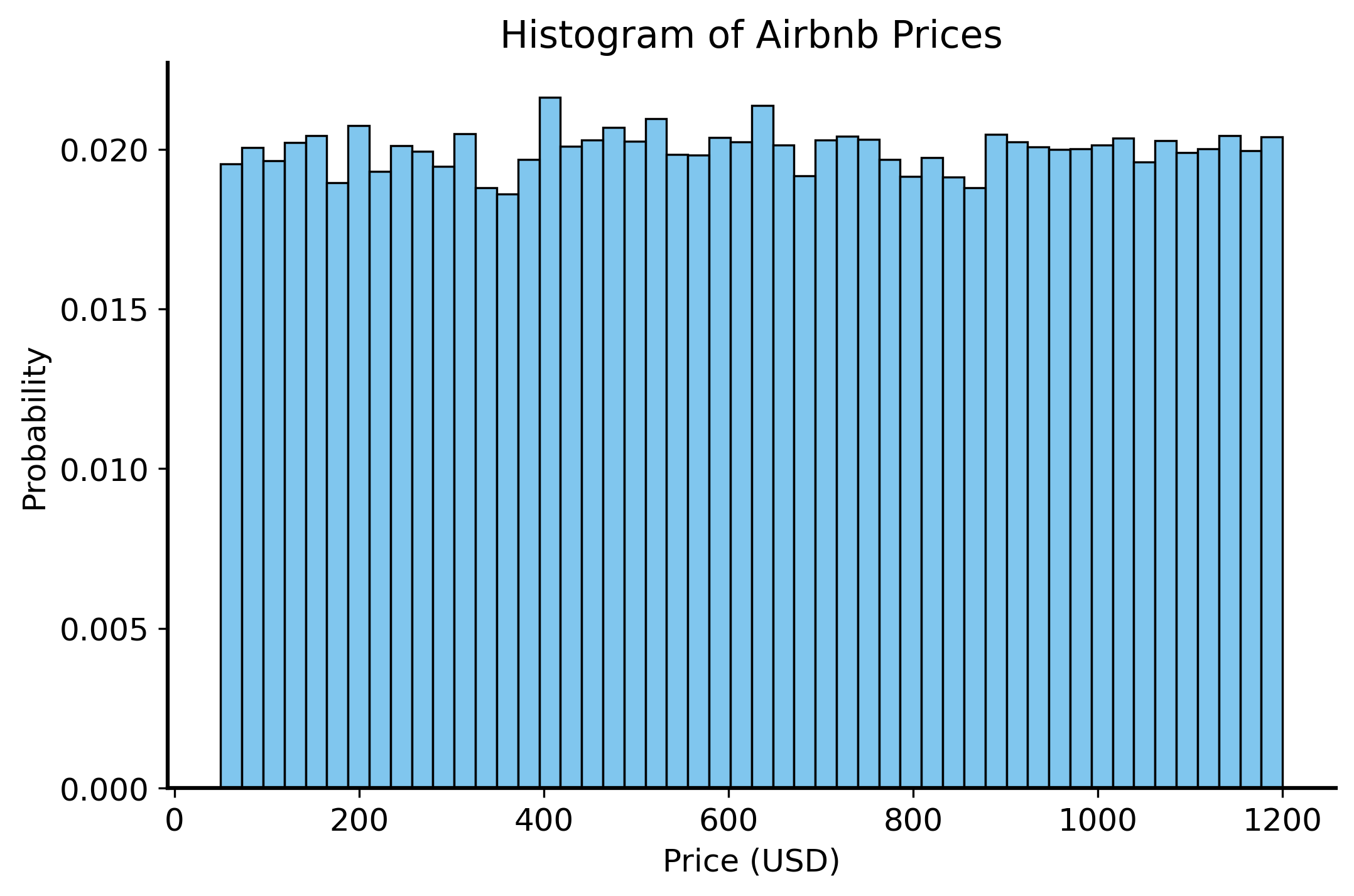
Airbnb prices histogram
The prices of Airbnb listings from back in the first lecture are a good example of a continuous random variable. The resolution (cents) is so small that basically every price is unique. So we cannot just count the number of occurrences of each price. Instead, we can create a histogram to visualize the distribution of prices across bins.
Area under a probability distribution
Area under a probability distribution
At the beginning of this lecture, we said that the probability of all possible outcomes must sum up to 1. This is true for both discrete and continuous random variables. For discrete random variables, the sum of the probabilities of all possible outcomes equals 1. For continuous random variables, the area under the probability density function (PDF) must equal 1.
For discrete: \[ \sum_{x} f(x) = 1 \] For continuous: \[ \int_{-\infty}^{\infty} f(x) \, dx = 1 \]
We can use the same idea to compute the probability of a continuous random variable falling within a certain range. For example, if we want to know the probability that a continuous random variable \(X\) falls between \(a\) and \(b\), we can compute the area under the PDF from \(a\) to \(b\): \[ \P(a \leq X \leq b) = \int_{a}^{b} f(x) \, dx \]
Expectation
We are often interested in the average value of a random variable.
- For example, if we play roulette, we might want to know the average amount of money we can expect to win or lose per game.
Why do we need an average?
- Since a random variable can take on many different values, a single sample does not give you a lot of information.
- You might win hundreds of dollars on one game, but this does not mean you will win that much every time you play.
Thinking about averages
Instead, think about what would happen if we repeated the random process many times and took the average.
- Values that occur more frequently will tend to have a larger impact on the average, while values that occur less frequently will have a smaller impact.
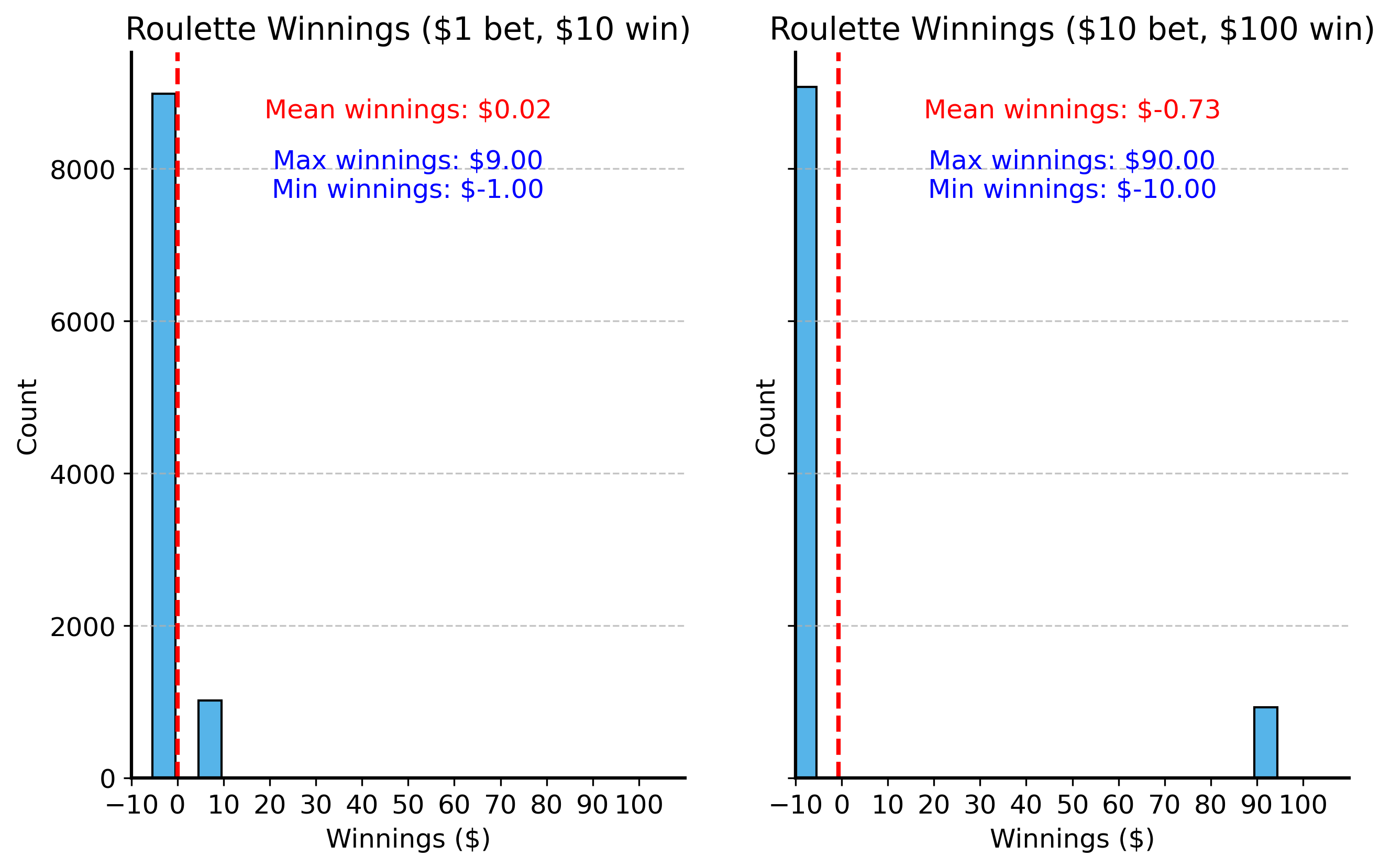
- For example, at a casino roulette table perhaps you place a bet that has a 10% chance of winning. You might bet $1 and win $10 ($9 net profit) on one game, but if you lose $1 on the next 9 games you’re not making money in the long run. Even though $9 profit sounds great, the fact that it happens so infrequently (and you lose $1 90% of the time) means that your average profit is actually zero.
Gambling warning
Gambling warning: the house always wins
Actually, at real casinos, the games are designed so that “the house always wins” in the long run. So they would not let you bet $10 to win $100 ($90 profit) with a 10% chance – they would give you worse odds, like a 9% chance of winning $100 for a $10 bet.
In the short term this is hardly noticeable – you’re actually quite likely to win a few times! But in the long term, the house edge means that you will lose money if you keep playing. This is why casinos are profitable businesses.
Expectation (formal definition)
We can formalize this idea that the average gives more weight to values that occur more frequently.
The expectation (or expected value) of a random variable \(X\) is gives the average value of \(X\) over many instances. It is denoted as \(\mathbb{E}[X]\) or \(\mu_X\). The expectation is calculated as follows: \[ \mathbb{E}[X] = \sum_{x} x \cdot f(x) \] where \(f(x)\) is the probability function of \(X\). For continuous random variables, the sum is replaced with an integral: \[ \mathbb{E}[X] = \int_{-\infty}^{\infty} x \cdot f(x) \, dx \]
Expectation as weighted average
The way to think about this is that the expectation is a weighted average of all possible values of \(X\), where the weights are the probabilities of each value.
So in our roulette example, you can either lose $1 (with 90% probability) or win $9 (with 10% probability). The expectation would be: \[ \begin{align*} \mathbb{E}[X] &= \sum_{x \in \{-1, 10\}} x \cdot f(x) \\ &= (-1) \cdot 0.9 + (10-1) \cdot 0.1 \\ &= -0.9 + 0.9 \\ &= 0 \end{align*} \]
Sample mean
This is also the same as what you get if you just take the average of the outcomes. Say we play roulette 10 times, and we win $10 on one game and lose $1 on the other 9 games. The average outcome is: \[ \begin{align*} \frac{1}{10} \left( -1 \cdot 9 + 9 \cdot 1 \right) &= -1 \cdot 0.9 + 9 \cdot 0.1 \\ &= -0.9 + 0.9 \\ &= 0 \end{align*} \]
So for a finite dataset, or set of outcomes, we can estimate the expected value by taking the average of the outcomes. This is often written as \(\bar{X}\), and referred to as the sample mean. \[ \mathbb{E}[X] \approx \bar{X} = \frac{1}{n} \sum_{i=1}^{n} x_i \]
This approximation becomes more accurate as the number of samples \(n\) increases. We will talk about this more in a future lecture.
Variance and standard deviation
The average is a useful summary of a random variable’s central tendency, but it does not tell us anything about how spread out the values are.
Consider the roulette example again. If we play roulette many times, it does not matter how much we bet on each game – the average amount we can expect to win or lose is always zero. You can bet $1 or $10,000 on each game, but the average outcome is still zero.
Of course, the outcome of each game is not zero. Sometimes you win, sometimes you lose, and the amount you win or lose changes drastically depending on how much you bet.
Roulette winnings visualization
Variance (intuition)
How can we quantify this spread?
- we want to capture that even though the average outcome is zero, winning $90 and losing $10 is very different from winning $9 and losing $1.
- maybe you want to pay for dinner with your winnings, so a $90 payout is much more useful than a $9 payout.
- maybe you only have $10 in your pocket, so you can’t afford to lose all of it on a single game.
We need a statistic that captures the typical distance between the values of the random variable and the average value.
Computing distance from average
So let’s compute exactly that - the distance from the average. The formula for distance between two vectors \(x\) and \(y\) is: \[ d^2 = \sum_{i} (x_i - y_i)^2 \] where \(x_i\) and \(y_i\) are the elements of the two vectors.
- This is like the Pythagorean Theorem for computing the length of athe hypotenuse of a triange (\(a^2 + b^2 = c^2\)).
In our case, we want to compute the distance between the values of the random variable \(X\) and the average value \(\mathbb{E}[X]\). \[ d^2 = \sum_x (x - \mathbb{E}[X])^2 \]
Average distance
Now we’re getting somewhere! However, this is adding up all of the squared distances – that means that the more values we have, the larger the distance will be.
This is not quite right – instead we want to compute the average distance from the mean in order to get a sense of how spread out the values typically are.
So we need to divide by the number of values: \[ d^2_\text{avg} = \frac{1}{n} \sum_x (x - \mathbb{E}[X])^2 \]
Something should feel familiar about this expression. Recall that the average is related to the expectation.
Variance formula
If we replace the average with the expectation, we get the formula for the variance of a random variable \(X\): \[ \text{Var}(X) = \sigma^2(X) = \mathbb{E}[(X - \mathbb{E}[X])^2] = \sum_x (x - \mathbb{E}[X])^2 \cdot f(x) \]
The variance tells us how spread out the values of a random variable are around the average.
- a larger variance means that the values are more spread out
- a smaller variance means that the values are closer to the average.
Standard deviation
The variance is a useful statistic, but it is not in the same units as the original random variable. For example, if \(X\) represents the amount of money you win or lose in dollars, then the variance is in dollars squared. This can make it difficult to interpret.
So we often take the square root of the variance to get the standard deviation: \[ \text{SD}(X) = \sigma(X) = \sqrt{\text{Var}(X)} = \sqrt{\mathbb{E}[(X - \mathbb{E}[X])^2]} \]
Like with expected value, we can replace the expectation with the sample mean to get an estimate of the standard deviation (or variance) from a finite dataset: \[ \hat{\sigma}(X) = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{X})^2} \]
Sample variance vs. population variance
Sample variance vs. population variance
Technically, the formula above is an imperfect estimate of the population standard deviation. It’s in general a little bit too small, because the sample mean \(\bar{X}\) does not perfectly represent the population mean \(\mathbb{E}[X]\). We can correct for this by dividing by \(n-1\) instead of \(n\): \[ \hat{\sigma}(X) = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{X})^2} \] This is called the sample standard deviation.
Why is the initial estimate too small? In a small dataset, the sample mean “overfits” the data, meaning it is closer to the individual data points than the true population mean.
Common probability distributions
Certain probability distributions are very common, and their corresponding probability functions are well-known. It is not necessary to memorize these distributions, but it is useful to be familiar with them and their properties.
| Distribution | Type | Parameters | Mean | Variance |
|---|---|---|---|---|
| Bernoulli | Discrete | \(p \in [0, 1]\) | \(p\) | \(p(1-p)\) |
| Binomial | Discrete | \(n \in \mathbb{N}, p \in [0, 1]\) | \(np\) | \(np(1-p)\) |
| Poisson | Discrete | \(\lambda > 0\) | \(\lambda\) | \(\lambda\) |
| Uniform | Continuous | \(a < b\) | \(\frac{a+b}{2}\) | \(\frac{(b-a)^2}{12}\) |
| Normal | Continuous | \(\mu \in \mathbb{R}, \sigma > 0\) | \(\mu\) | \(\sigma^2\) |
| Exponential | Continuous | \(\lambda > 0\) | \(\frac{1}{\lambda}\) | \(\frac{1}{\lambda^2}\) |
Visualizing distributions
Summary
This lecture introduced many important concepts from probability theory that will be useful throughout the course. Probability gives us a mathematical language and toolkit for reasoning about uncertainty and randomness in data, by thinking about possible outcomes and their likelihoods.
In particular, we covered:
- The basic definition of probability and how to compute it for simple events.
- The addition and multiplication rules for calculating probabilities of multiple events.
- The concept of independence and how it affects probabilities.
- Random variables and their probability distributions
- The expectation (or expected value) of a random variable
- Variance and standard deviation
Going forward, these concepts will be foundational for statistical modeling and designing good simulations and statistical tests.
Assignment 2 will give you a chance to work through some of these concepts in more detail, so be sure to check it out!